fb死機元兇 路由器出錯 全球斷線6小時 通訊平台齊癱瘓
原文刊於信報財經新聞「StartupBeat創科鬥室」

fb死機6個多小時後,於本港時間昨晨近6時才回復正常。(路透資料圖片)
全球最大社交網站Facebook(fb),以及旗下即時通訊程式fb Messenger、WhatsApp、圖片社交網Instagram等多個平台,於本港時間周一午夜前集體死機,斷網6個多小時後才恢復正常。fb事後在官網交代,指事故因協調數據中心網絡流量的骨幹路由器(Backbone Router)配置改變出錯所致。
網絡事故偵測網站Downdetector顯示,截至昨晨(5日)6時半,全球累計接獲1400萬宗事故報告。最多網民報告的地區,依次為美國、德國、荷蘭、英國、意大利及加拿大等。此外,拉丁美洲、南非、印度、澳洲、東南亞、南韓、日本及香港用戶亦大受影響。

有保安專家認為fb今次癱瘓,或者跟網域名稱系統(DNS)有關。(Facebook網站圖片)
朱克伯格貼文致歉
fb創辦人兼行政總裁朱克伯格(Mark Zuckerberg)其後貼文為事故致歉,強調了解用戶信賴公司服務。fb工程及基礎設備副總裁賈納丹(Santosh Janardhan)在網誌解釋,網絡流量中斷對數據中心的通訊產生連鎖影響,更牽涉日常營運的多個內部工具及系統,幸而未有證據顯示用戶數據因此外洩。
有保安專家認為fb今次死機,可能跟網域名稱系統(DNS)有關,無法把人類可讀的網址轉換為供機器閱讀的IP地址。

當fb服務突然停擺時,心急如焚的網民,積極物色替代方案。(Facebook網站圖片)
美國互聯網服務公司Cloudflare分析指出,fb的邊界閘道器協定(BGP)最先出事,於香港時間周一晚上11時40分,其更新密度比平日多近250倍,未幾就爆出連線困難;至周二早上5時28分,DNS才再次正常運作。
BGP主要幫助網絡選擇最佳路徑以傳輸流量。Cloudflare補充,全球近50億互聯網活躍用戶,由數百萬個系統及協議協同工作,是一個非常複雜、且相互依賴的系統。當fb未有透過BGP宣布其存在,其他的互聯網服務供應商(ISP)就無法跟fb建立路由連接,瞬間把全球用戶拒諸門外。
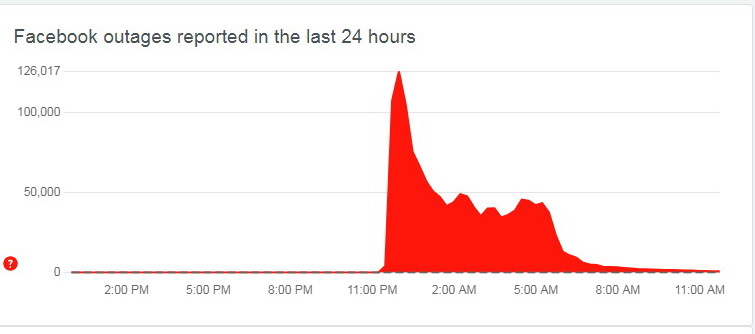
Downdetector顯示,截至昨晨(5日)六時半,該平台在全球接獲1400萬宗事故報告。(Downdetector網站圖片)
替代通訊程式下載激增
今次網絡事故牽連甚廣,用戶不停為應用程式連線,反覆加載頁面,造成流量連鎖效應。由於部分第三方網絡服務需以fb賬戶認證登入,例如智能電視、恒溫器等設備,相關服務也被波及。Cloudflare的數據指出,fb一系列網站服務死機後,該平台處理的查詢個案比平時多近30倍。
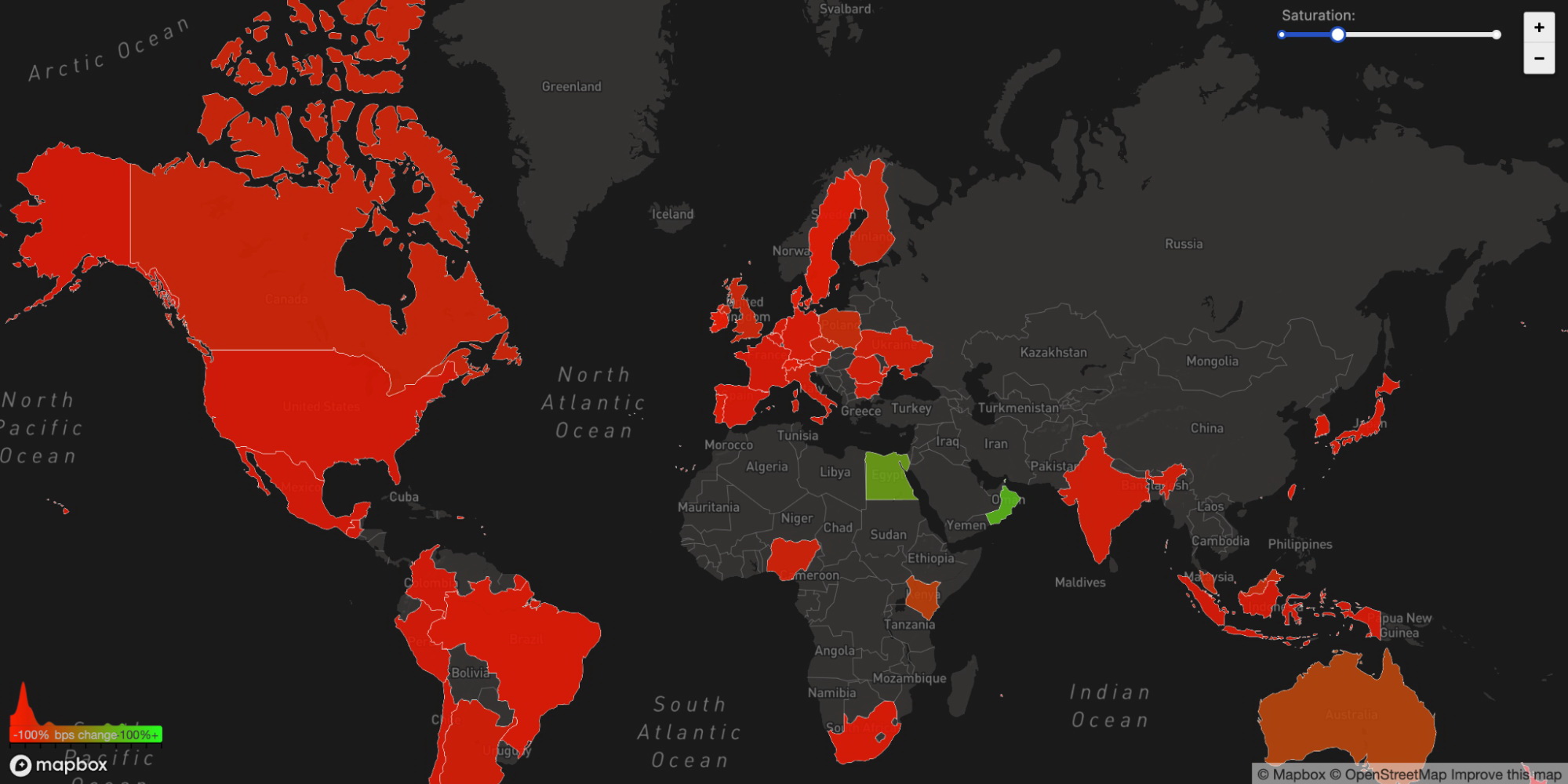
英美、加拿大、歐洲等國家,為今次fb斷網事故重災區。(Cloudflare網站圖片)
由於fb相關平台陣容龐大,當突然在網上消失,心急如焚的網民只好尋找替代方案,Twitter、 Signal、Telegram及TikTok等社交媒體平台在這個時段的DNS查詢同步增加,或導致其他平台出現延遲、超時等問題。
fb過去已爆出多次故障,上次大規模斷線可追溯至2019年,當時因技術問題令服務受阻24小時。今次事故發生後,fb周一股價受壓,曾急跌5.9%,收市仍挫4.89%,收報326.23美元。
延伸閱讀:
港專家稱事不尋常 fb未釋疑團
支持EJ Tech


如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。



















{kind=link}
{kind=link}