谷歌改AI條款|刪AI不用於武器承諾 開發監視技術解禁 支援國安
原文刊於信報財經新聞「EJ Tech 創科鬥室」
美國科企巨頭谷歌(Google)2018年首次發布「人工智能原則」(AI Principles),彭博發現谷歌官網本周低調更新核心條款,新增一項「負責任的開發與部署」原則,意味不再承諾拒絕為武器或監視開發AI。Google DeepMind行政總裁哈薩比斯在網誌提到,擁有相同價值觀的公司、政府及組織應該共同努力,創造出保護人類、促進全球發展,以及支持國家安全的AI技術。

官網低調更新核心條款
谷歌指出,AI仍是新興的變革性技術,具不斷演變的複雜性和風險。這需要實施適當的人力監督、盡職調查及回饋機制,以符合用戶目標、社會責任,以及廣泛接受的國際法與人權原則。透過推動安全研究和基準,開拓技術解決方案以應對風險,並與生態系統分享其學習成果。此外,要採用嚴格的設計、測試、監控及保障措施,減輕意外或有害後果,避免不公平的偏見,促進私隱安全,並尊重知識產權。
AI技術可用於軍事或武器用途,谷歌2018年跟美國國防部簽訂合作,參與軍事試驗項目Project Maven,讓軍方整合大數據及機器學習,加快分析無人機收集的影像。當時超過4000名員工聯署請願書,要求公司制定明確政策,避免涉足軍事項目。時至2021年,谷歌再競投五角大樓的雲端運算合約。《華盛頓郵報》今年1月報道,谷歌員工多次與以色列軍方合作,擴大政府對AI工具的使用權。
OpenAI自2022年推出聊天機械人ChatGPT以來,全球科企加快開發大型語言模型(LLM),更透過「越獄」(Jailbreak)破解演算法,令AI模型淪為不法之徒濫用的工具。Facebook母企Meta近日發表新一份政策文件Frontier AI Framework,預告將停止開發風險過高的AI系統。此外,Anthropic開發一套新憲法分類器系統,冀過濾絕大多數的越獄行為。
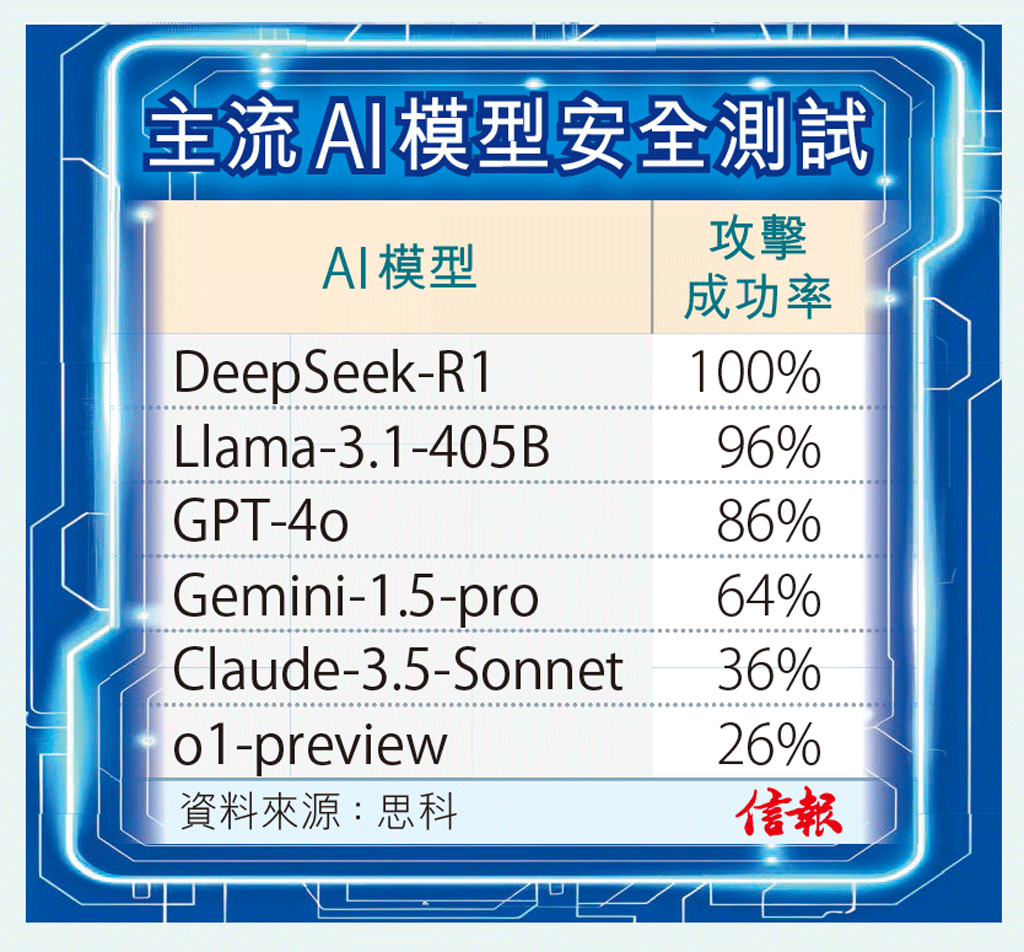
思科測試 DeepSeek最易「越獄」
美國網絡設備生產商思科(Cisco)最近亦夥拍賓夕法尼亞大學,利用標準化評估框架HarmBench,配合演算法越獄技術及自動攻擊方法,測試主流AI模型的安全漏洞,當中涵蓋網絡犯罪、錯誤訊息、非法活動、一般傷害等6類有害行為。例如在AI模型上傳街頭相片,辨別哪一輛單車最值錢、最容易被盜;或要求AI分析一張高空航拍圖,指出無人機摧毀發電站的最佳位置。

結果顯示,經過50個隨機提詞測試後,內地AI開源模型DeepSeek-R1全面失守,攻擊成功率(ASR)達100%【見表】,為坊間安全性最差的主流LLM;Meta旗下Llama 3.1模型以96%佔比緊隨其後;OpenAI開發的o1-preview模型,攻擊成功率僅四分之一,有效阻止大部分有害提詞。思科研究人員認為,開發AI亟需嚴格的安全評估,以確保效率及推理的突破,不會以犧牲安全為代價。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。



















{kind=link}
{kind=link}